textpub.neocities.org . [ записки: обучаюсь C++ ]
Из моих записок про самообучение C++. Дата первой публикации: 18.01.2019. Дата последней редакции: 25.01.2019.
Консольная программа выдает кракозябры 2
Первый способ решения проблемы
Начало можно прочитать в предыдущей записи. В ней рассмотрена проблема, ее причины и коротко перечислены способы ее решения. Итак, первый способ решения проблемы — привести исходный текст программы в кодировку, на которую настроен интерпретатор командной строки Windows 7 (cmd.exe), то есть в кодировку 866 (вики).
Во-первых, можно подготовить файл с исходным текстом программы в стороннем редакторе, умеющем работать с разными кодировками. Например, я использую в этом качестве программу «Notepad++». Полученный файл с расширением .cpp в кодировке «OEM 866» включаем в проект «Visual Studio Community 2017», как я уже описывал. Запускаем сборку решения и получаем исполняемый файл, выводящий фразу на русском правильно.
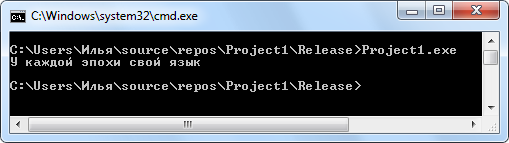
При этом, если открыть включенный в проект файл в «Visual Studio Community 2017» для редактирования, вместо русских букв всё равно можно увидеть кракозябры. Как с этим справиться, рассмотрим ниже.
Во-вторых, в среде «Visual Studio Community 2017» тоже можно работать с разными кодировками. Как уже упоминалось, когда в Windows 7 выбран язык системы «Русский (Россия)», по умолчанию среда «Visual Studio Community 2017» интерпретирует открываемые файлы в кодировке 1251, в ней же сохраняет вновь создаваемые в среде исходные тексты программ.
Отображение текстов программы в разных кодировкахЧтобы среда отобразила исходный текст программы не в кодировке по умолчанию (в нашем случае — 1251), а, к примеру, в нужной нам кодировке 866, в «Обозревателе решений» правой кнопкой мыши по имени файла с исходным текстом программы вызовем контекстное меню и выберем пункт «Открыть с помощью...». Откроется окно со списком редакторов среды «Visual Studio Community 2017». В этом списке для исходных текстов программ на языке C++ есть два редактора: «Редактор исходного кода C++» и «Редактор исходного кода C++ (с кодировкой)», первый из которых при открытии файла ничего у пользователя не спрашивает, а второй запрашивает, в какой кодировке нужно показать открываемый файл. Любой из редакторов списка в окне можно назначить основным кнопкой «По умолчанию» справа от списка.
Выберем «Редактор исходного кода C++ (с кодировкой)» и нажмем кнопку «OK». Откроется список кодировок, в котором выберем пункт «Кириллица (DOS) - кодовая страница 866». Среда откроет исходный текст программы для редактирования и отразит его в указанной кодировке. Важно понимать, что при открытии файлов среда не изменяет исходный файл, не производит никаких перекодировок исходного содержимого, а лишь интерпретирует исходный текст в указанной кодировке и в ней же дает редактировать.
Создание нового файла с текстом программы в разных кодировкахВ рамках проекта «Visual Studio Community 2017» создание и включение нового файла в проект происходит одновременно. При этом если основным выбран «Редактор исходного кода C++ (с кодировкой)», то перед созданием файла среда попросит указать желаемую кодировку исходного текста программы в этом файле.
Перекодировка существующего текста программыЯ как раз таки изначально и набрал текст программы в «Visual Studio Community 2017», не задумавшись, что кодировка по умолчанию в среде в нашем случае — 1251. Чтобы сохранить текст программы в файле Source.cpp в кодировке 866, откроем пункт меню «Файл — Сохранить Source.cpp как...». В открывшемся окне нажимаем на правую часть кнопки «Сохранить |▼» и в открывшемся списке выбираем пункт «Сохранить с кодировкой...». На вопрос среды о замене версии файла со старой кодировкой отвечаем положительно. Далее откроется окно «Дополнительные параметры сохранения», в котором можно выбрать из списка нужную кодировку. Выбираем пункт «Кириллица (DOS) - кодовая страница 866» и нажимаем кнопку «OK». Файл перезапишется в новой кодировке. Важно понимать, что в файл в новой выбранной кодировке запишется то, что отображено на экране редактора среды, а не изначальное содержимое файла.
Несколько кодировок в одном файле с исходным текстом программыБывает, что в одном файле необходимо хранить текст в разных кодировках. Сделаем в нашей простейшей консольной программе вывод одной и той же фразы в кодировках 1251 и 866. Откроем программу сначала в одной кодировке, наберем нужную фразу, а затем откроем эту же программу в другой кодировке и наберем аналогичную фразу.
Полученная программа, отображенная в кодировке 1251:
#include <iostream>
using namespace std;
int main()
{
cout << "“ Є ¦¤®© нЇ®еЁ бў®© п§лЄ\n"; // OEM 866
cout << "У каждой эпохи свой язык\n"; // ANSI 1251
return 0;
}
Та же программа, отображенная в кодировке 866:
#include <iostream>
using namespace std;
int main()
{
cout << "У каждой эпохи свой язык\n"; // OEM 866
cout << "╙ ърцфющ ¤яюїш ётющ ч√ъ\n"; // ANSI 1251
return 0;
}
Результат работы этой программы (тут первый способ решения проблемы продемонстрирован более наглядно, чем ранее):
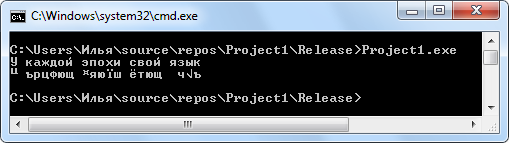
Функции перекодировки текста
В Windows API для этих целей существуют функции (а точнее, макросы) CharToOem и OemToChar, а также CharToOemBuff и OemToCharBuff (в документации рекомендуется использовать последние). Они предназначены для перекодировки текста из кодировки группы OEM в кодировку группы ANSI и наоборот.
Некоторые предпочитают решать проблему кракозябр с помощью этих функций. Пример такой программы, отображенной в кодировке 1251:
#include "windows.h" // для работы с функциями перекодировки #include <iostream> using namespace std; int main() { char str[80] = "У каждой эпохи свой язык\n"; // ANSI 1251 CharToOemBuff(str, str, 80); // перекодировка из ANSI в OEM cout << str; // вывод на экран в кодировке OEM 866 return 0; }
Результат работы этой программы:
Мне кажется, использование функций перекодировки в данном случае — это лишнее усложнение программы, проще изначально писать программный код в нужной кодировке (в нашем случае — в 866), как было описано выше.
Выводы
Программист всегда должен понимать, в какой кодировке хранится текст программы, в какой кодировке текстовый редактор отображает текст программы и в какой кодировке нужно вывести текст на устройства вывода, чтобы тот отразился правильно. Не зная этих трех вещей, бездумно применяя любой из порекомендованных способов решения проблемы, можно каждый раз получать неправильный результат в виде кракозябр.
Например, описанный здесь первый способ решения проблемы работает в «Windows 7 Профессиональная» только при выбранном языке системы («system locale») «Русский (Россия)» (кратко — «ru-RU»), то есть только когда используются кодировки 866 и 1251 из групп кодировок OEM и ANSI.
Чтобы проверить это утверждение, я переключил язык системы на «Английский (США)» через «Панель управления» (как это сделать, я описал в предыдущей записи). Не путаем «язык системы» и «язык интерфейса».
В результате вышеописанные программы, работавшие при языке системы «Русский (Россия)», при языке системы «Английский (США)» выдали следующее:
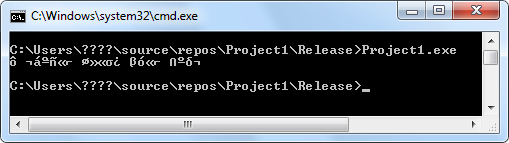
1) вариант, при котором выводимая фраза в тексте программы была сохранена в кодировке 866:
2) вариант с функцией CharToOemBuff:
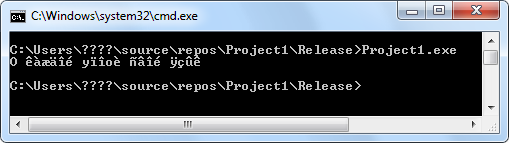
Это произошло оттого, что в первом случае программист выводит текст, рассчитывая на кодировку 866, а командная строка интерпретирует выводимое в кодировке 437 (вики), в которой вообще нет русских букв; во втором случае функция CharToOemBuff на вход получает строку в кодировке 1251, но воспринимает ее как строку в кодировке 1252, ведь программист рассчитывал, что функция будет преобразовывать строку в кодировке 1251 в кодировку 866, а после переключения языка системы она преобразовывает кодировку 1252 в кодировку 437.