textpub.neocities.org . [ записки: обучаюсь C++ ]
Из моих записок про самообучение C++. Дата первой публикации: 15.01.2019. Дата последней редакции: 13.02.2019.
Консольная программа выдает кракозябры
Собрав и запустив свою первую консольную программу на C++ под Windows (см. предыдущую запись), начинающий сталкивается с еще одной проблемой: вместо осмысленной фразы по-русски (с латиницей этой проблемы нет) на выходе получается нечитаемый текст — кракозябры (по-английски «mojibake»).
Текст нашей простейшей программы по Лафоре:
#include <iostream>
using namespace std;
int main()
{
cout << "У каждой эпохи свой язык\n";
return 0;
}
Результат работы этой программы при запуске из командной строки Windows (я работаю под «Windows 7 Профессиональная» с установленным SP1):
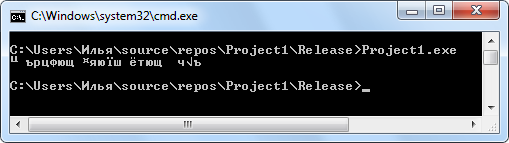
Причина проблемы
Так как компьютер воспринимает только числа, программистам для работы с текстом изначально пришлось представить буквы и знаки препинания числами. Для этого были составлены таблицы соответствия символов числовым кодам. Одной из самых известных таких таблиц является ASCII, разработанная и стандартизированная в США в 1963 году.
Эта таблица включает 128 значений, потому что технически для представления символов в распоряжении программистов на тот момент было лишь 7 бит (27 = 128). Так как кроме, собственно, прописных и строчных букв, цифр и знаков препинания в таблицу нужно было включить управляющие символы и различные специальные символы, то закодировать можно было только символы одного алфавита. А раз дело происходило в США, то и алфавит, ествественно, взяли латинский.
Позже для представления символа в компьютере стали применять 8 бит (один байт) и число значений в таблице стало возможным расширить до 256 значений (28 = 256). Появились расширенные таблицы ASCII, первые 128 значений (коды 0-127) которых совпадали с изначальной таблицей ASCII и содержали латинский алфавит, а во второй части (коды 128-255) программисты-пользователи других алфавитов кодировали свой алфавит.
Из-за того, что поначалу не существовало единого стандарта, даже для одного алфавита могло быть создано и распространено несколько несовместимых вариантов расширенных таблиц ASCII. Например, даже сегодня в Windows 7 еще поддерживаются две группы кодировок — OEM и ANSI. Кодировки из этих групп являются вариациями расширенной таблицы ASCII. (Кстати, в литературе по этой теме можно запутаться в терминах-синонимах. По-моему, кодовая страница (code page), набор символов (character set) и кодировка (character encoding) — это примерно одно и то же.)
В итоге для решения проблемы путаницы кодировок была придумана универсальная кодировка, ставшая известной под названием Юникод (Unicode). Первая версия стандарта Юникода вышла в 1991 году. Первые 128 значений в таблице Юникода совпадают с ASCII, точно так же, как и в расширенных таблицах ASCII. Однако, в Юникоде для кодирования символов используется больше 8 бит, поэтому кодовое пространство единой таблицы состоит из более миллиона позиций, в которые удалось поместить все известные алфавиты мира. В идеале все программы должны использовать Юникод, но тут есть две проблемы: 1) сам Юникод имеет несколько форм представления (UTF-8, UTF-16, UTF-32 и так далее) и разные несовместимые реализации в разных программах, что создает путаницу; 2) производители операционных систем хотят поддерживать и старые программы, вместо Юникода использующие не универсальные старые кодировки.
Итак, вернемся к нашей проблеме. В Windows 7 для программ, не работающих с Юникодом, в реестре назначены кодировки по умолчанию: для программ, работающих в текстовом интерфейсе — из группы кодировок OEM; для программ, работающих в графическом интерфейсе — из группы кодировок ANSI. Конкретные номера кодовых страниц зависят от «языка системы» (он же «system locale»). Не путать с «языком интерфейса» (он же «display language» или «interface language»).
Язык системы можно поменять через «Панель управления — Часы, язык и регион — Язык и региональные стандарты — вкладка «Дополнительно» — раздел «Язык программ, не поддерживающих Юникод». Например, при выбранном языке системы «Английский (США)» кодовые страницы по умолчанию для программ с текстовым интерфейсом (группа кодировок OEM) и программ с графическим интерфейсом (группа кодировок ANSI) будут 437 и 1252 соответственно. Для нашего языка системы — «Русский (Россия)» — соответствующие идентификаторы кодовых страниц — 866 и 1251.
То есть для интерпретатора командной строки Windows 7 (cmd.exe) кодовая страница по умолчанию в данном случае — 866. Нашу же программу мы набираем в среде «Visual Studio Community 2017», которая по умолчанию сохраняет текст программы в кодовой странице 1251. Так как первые части (коды 0-127) у этих кодировок (это уже отмечалось выше) совпадают, а именно в этих частях закодирован латинский алфавит, то фраза, выводимая латиницей, будет отображена правильно. Фраза на русском языке, как в нашем случае, отображается кракозябрами, потому что вторые части кодовых страниц 866 и 1251 (коды 128-255), в которых закодирован русский алфавит, не совпадают.
Способы решения проблемы
Таких способов предлагается три. Перечислю в порядке увеличения сложности:
1) привести исходный текст программы в кодировку 866 (дополнительно рассмотрены функции перекодировки CharToOemBuff и OemToCharBuff);
2) оставить исходный текст программы в кодировке 1251, добавить в программу операторы, указывающие командной строке выводить текст в кодировке 1251 (в том числе с помощью функции setlocale, с помощью функций SetConsoleOutputCP и SetConsoleCP и с помощью функции system и команды chcp);
3) настроить командную строку для работы с Юникодом, привести исходный текст программы в кодировку Юникода, добавить в программу операторы, указывающие командной строке выводить текст в кодировке Юникода — рассмотрено тут.
Подробнее эти способы разберем в следующих записях.